Reliability is the new model selection: what HN and Reddit tell us about production AI agents in 2026

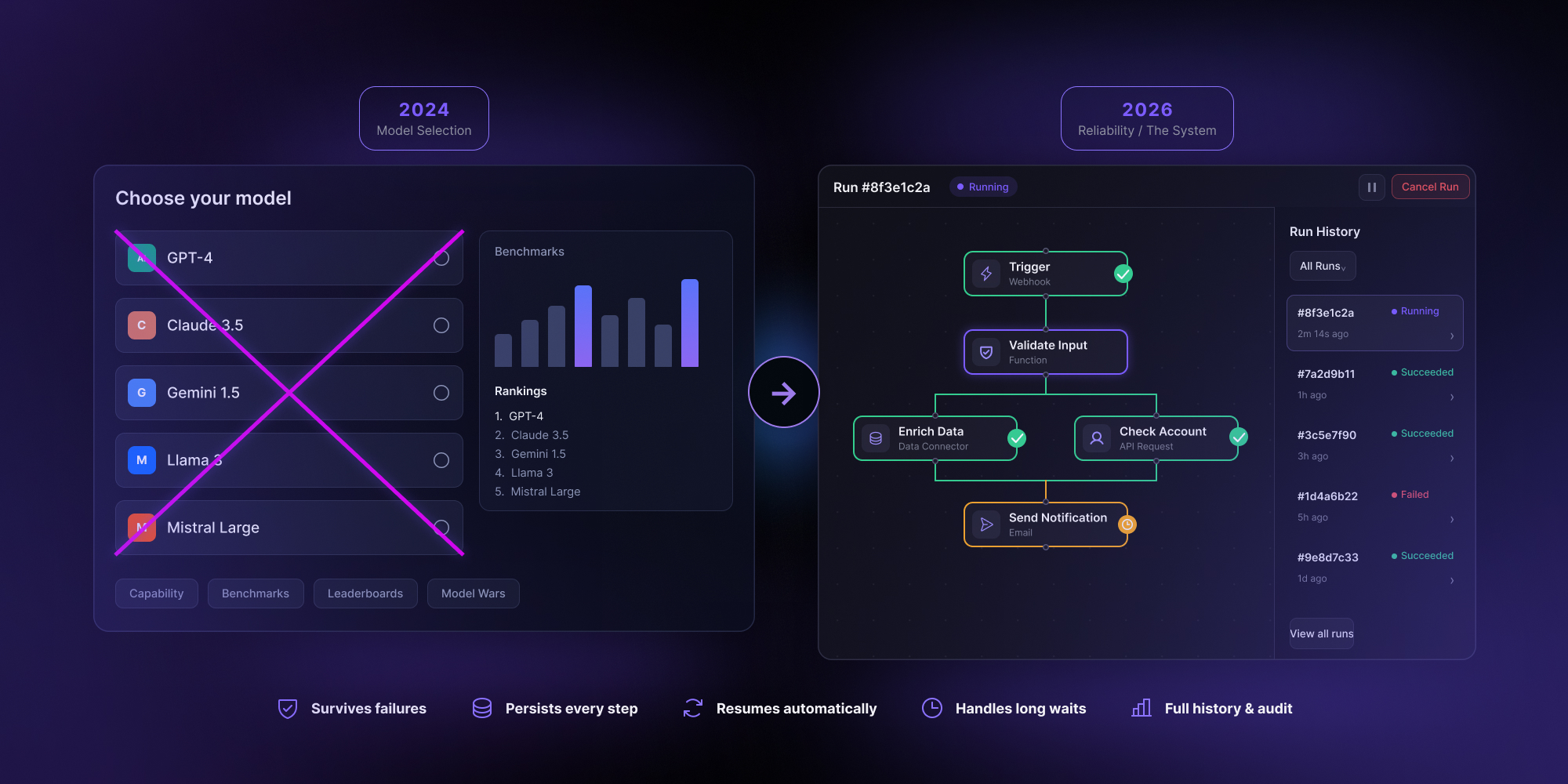
In 2024 the forums argued about models. GPT-4 or Claude. Llama or Mistral. The benchmark wars filled every thread, and the winning move was picking the right brain for the job.
Two years later the argument has moved. The model is rarely the bottleneck now. Reliability is.
Open Hacker News today and the pattern is hard to miss. The loud threads are not about capability.
They are about a state that vanished on a restart.
Retries that fired twice.
A long task that ran for hours and produced nothing you could trust.
The model did its part. Yet, the system around it did not.
The vendor closest to this shift describes the same move. Temporal says its customers stopped asking how to make a workflow more reliable and started asking how to build an AI system that "doesn't fall apart in production." In February 2026 the company raised a $300M Series D at a $5B valuation.
Its product is not a model. It is infrastructure for durable execution: the layer that lets a long-running process survive a crash and resume where it stopped.
When that layer raises a round that size, it tells you where the pain moved.
This piece reads the room. We went through Hacker News and Reddit, plus the public writing of the people building this layer, and the signal is consistent. The community stopped asking which model. It started asking how to make the thing reliable.
That question has a decades-old answer in distributed systems. It also has a fresh gap. Durable execution fixes the back end. It does not give you a way to see, author, and ship the workflow that runs on top. That gap is the subject of the last third of this piece.
What Hacker News is arguing about
On HN the capability debate is mostly settled. The reliability debate is wide open, and it splits into a few recurring threads.
Durable execution is the cheap win, with a catch. Engineers who adopted it talk about it the way you talk about a tool that paid for itself. One puts it simply, that Temporal "encodes much higher reliability into your system, almost for free" (bitexploder).

The catch lands in the same thread, from a developer shipping business-critical systems at Fortune 500 scale. The reliability is real, but only if "you do have to work hard and make everything idempotent" (inglor).

That is the whole game in one sentence. The infrastructure gives you durability. You still have to make every side effect safe to repeat.
Frameworks wear thin once the work gets specific. The canonical reference is the much-cited thread "Why we no longer use LangChain," from the Octomind team. The complaint is not that the framework fails on the simple case. It is that past the simple case you wade through several layers of abstraction to change one detail, and you lose sight of what the system is actually doing. The thread is old by AI standards, but the frustration it named only grew through 2025, as teams pushed agents from demo into production.
And the explicit claim, stated plainly, is that the bottleneck is not the model. As one commenter writes, "I don't think this is bottle necked on model quality" (jillesvangurp).

The context there is broad, about where AI agents struggle in general, but it captures the mood. Swapping in a smarter model does not fix a system that loses its place on restart.
It is worth noting how the conversation framed itself. One of the threads that set the tone carried the title "Less capability, more reliability, please." That is a headline, not a verdict from any single engineer. But titles on HN are chosen by submitters and voted up by readers, and this one rose because it named what people were feeling.

What Reddit shows from the trenches
Reddit is where the lessons get specific, and the specifics are about plumbing, not intelligence. Treat what follows as signal from practitioners, not as the load-bearing proof. The market data carries that weight. The forum posts tell you how it feels at the keyboard.
The expensive failures are the ones with side effects. In a recent r/LangChain thread on retries, a builder describes the exact nightmare. An agent crashed mid-run, restarted, and "sent the same email twice to a customer" (Kanyeweek67).
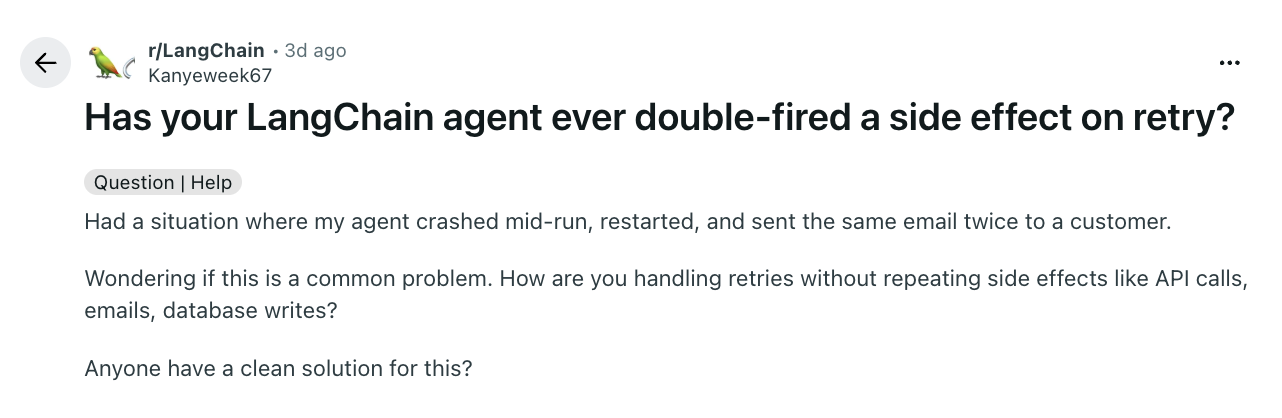
The replies do not argue. They generalize. "Retries are inevitable. Duplicate side effects don't have to be" (slingala). That is the design principle hiding inside the war story. You cannot prevent the crash and the retry. You can make the action safe to run twice.
The reason teams get this wrong is that they trust the wrong record. Many store the conversation and assume it tells them what happened. It does not. As one commenter puts it, conversation history is "an unreliable receipt" (ultrathink-art).
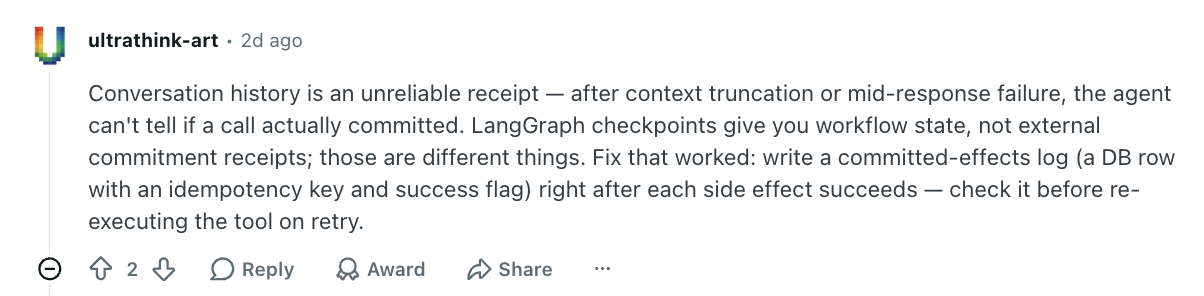
The model said it sent the email. Whether the send actually committed is a separate fact, and the chat log does not know it. Durable, checkpointed state knows it… but a transcript does not.
Three short comments, one thread, and the whole shape of the problem.
The agent reasoned fine.
The execution around it did not hold.
Why this shift, why now
Three forces pushed reliability to the top of the stack in 2026.
Scale and the arithmetic of failure
Agents left the demo and met real traffic, and the failure rate followed them. Gartner expects more than 40% of agentic AI projects to be canceled by the end of 2027, citing cost, unclear business value, and weak risk controls. The same firm expects 40% of enterprise applications to include task-specific AI agents by the end of 2026, up from under 5% in 2025.
Adoption and mortality are climbing together, and the reason is arithmetic. Reliability compounds the wrong way across steps. Even a generous 85% success rate per step lands at roughly 20% over ten steps, because 0.85 to the tenth power is about 0.197. A long agent does not fail because one step is dumb – it fails because small error rates multiply, and a ten-step chain is now a short one.
The stack matured enough to fix it
Durable execution crossed into the early majority in 2025. Inngest points to AWS Durable Functions, Cloudflare Workflows, and the Vercel Workflow DevKit as signs of the shift. Vercel describes its model as one for long-running, durable, observable agents that hold state, call tools, and survive interruptions and restarts.
The frameworks moved too. LangGraph now presents durable execution as a core capability for long-running, stateful agents. Pydantic AI officially supports durable execution integrations across Temporal, DBOS, Prefect, and Restate. OpenAI’s Agents SDK ecosystem has moved in the same direction through documented Temporal integration for production agents.
The migration path is becoming familiar. Teams start with retries or ad hoc checkpointing, then discover that production agents need state, replay, and failure recovery in the execution layer. In a WorkOS interview, Temporal co-founder Maxim Fateev describes the same failure mode: ephemeral agents fail mid-task, lose the run, and leave teams retrying from scratch or maintaining their own checkpointing logic.
Money and acquisitions concentrated around the layer
Temporal raised its round. Workday acquired Flowise and later signed a definitive agreement to acquire Pipedream, extending its agent and integration layer. IBM moved to acquire DataStax, the parent company of Langflow, after DataStax had earlier acquired the team behind Langflow. When capital and acquisitions cluster around agent infrastructure, it is a sign that the category is moving from experiments into platforms.
The honest read comes from someone with nothing to sell in this paragraph.
Kai Waehner argues the durable execution market is still near the start of its curve, not the end. Early, not late. That matters for anyone deciding where to build, because the slots above the engine are not filled yet.
What the people building this layer say
Step back from the threads, and the experts converge on one point. The model is no longer the hard part.
Maxim Fateev, co-founder and CTO of Temporal, states the production problem plainly. “A lot of teams are experimenting with AI agents right now, but running them reliably in production is still a major challenge,” he said when Temporal and OpenAI announced their Agents SDK integration. The hard part is not only model output. As Fateev puts it, teams have to think about “state, retries, and coordination” — the parts that become painful at scale.
In a WorkOS interview recap, the deeper issue is framed as visibility. A long multi-step agent needs an operator to inspect its state, understand what it has already done, and step in when something goes wrong. Temporal’s event history gives teams that audit trail by default, recording decisions, activity executions, and signals along the way.
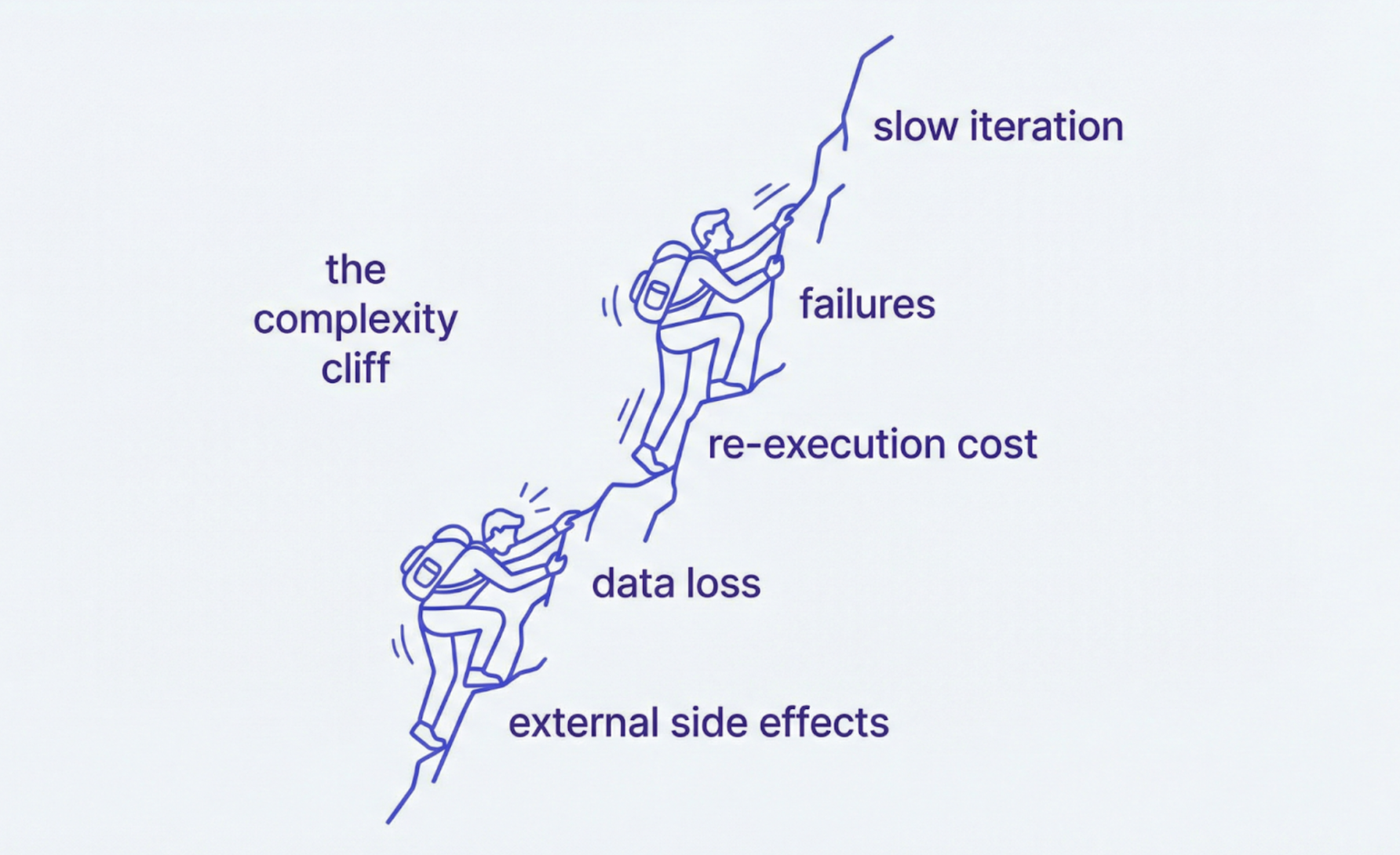
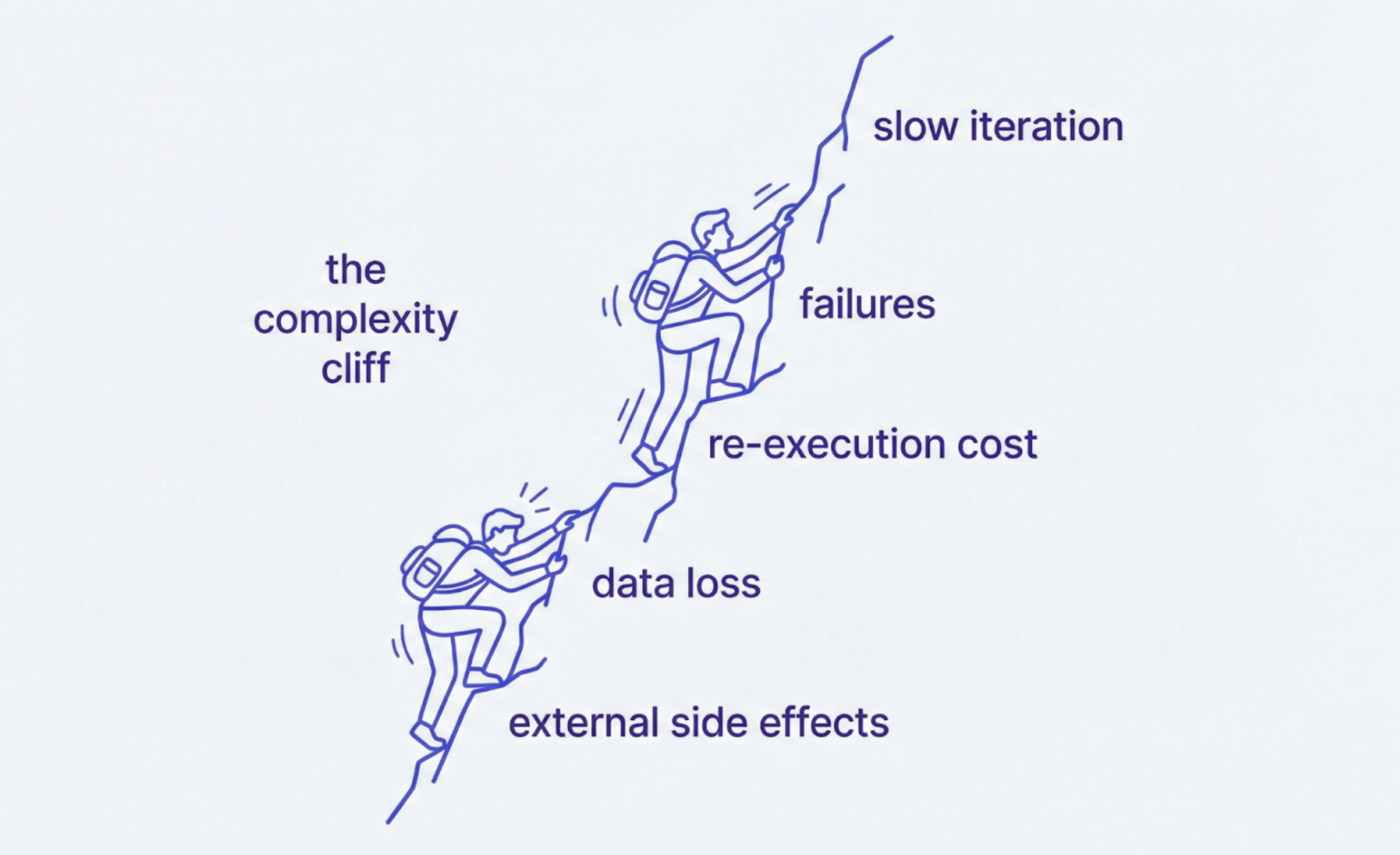
Temporal’s own engineering writing makes the systems case without much gloss. Long-running agents cross a “complexity cliff”: once work runs for minutes or hours and failure cost rises, teams need durable execution. Standard patterns like cron, queues, and manual checkpointing do not resume work with full context intact. Temporal’s example is blunt: if an agent fails after processing 9,999 of 10,000 SEC filings, restarting from the beginning wastes time, tokens, and API calls; rebuilding state from event history avoids that rerun.
The framing has spread beyond vendor docs. Engineering writing outside the vendor ecosystem is making a similar point: production agents are model-plus-system products. The model matters, but reliability depends on the harness around it — tools, memory, orchestration, guardrails, context, and recovery. Trade press tells the same story from enterprise deployments. VentureBeat quotes Preeti Somal, Temporal’s SVP of Engineering, saying teams rushed first-generation agents into production, “didn’t take care of the plumbing,” watched things “crash and burn,” and came back to rebuild on a reliable foundation.
Academia is naming the layer too. A 2026 paper on AI Runtime Infrastructure describes “a distinct execution-time layer that operates above the model and below the application,” one that observes, reasons over, and intervenes in agent behavior while the agent is running. Different words, same idea: there is a layer here, and it is not the model.
Where the visual authoring layer fits
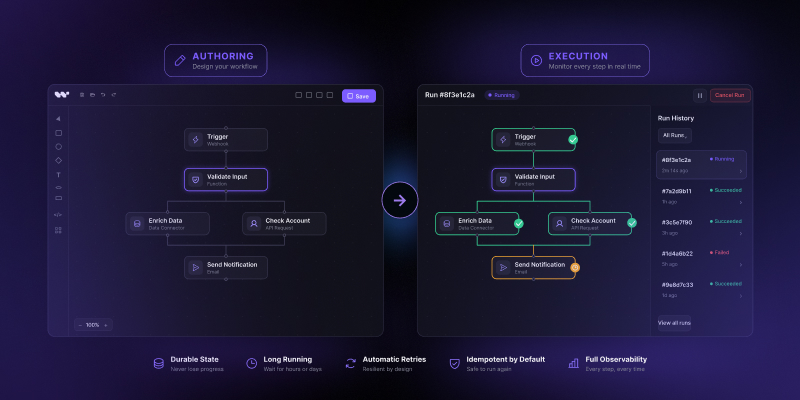
So durable execution wins the reliability argument. That settles one layer. It does not settle all of them.
Durable execution makes the back end survive. It does not make the workflow legible to anyone who is not an engineer.
Three gaps stay open after you adopt it.
#1 Authoring
The control plane is code. A product manager, a solutions engineer, or a domain expert who knows the actual process cannot read or change a code-defined graph. They file a ticket and wait. The people who understand the workflow are not the people who can edit it.
#2 Visibility
The dashboards that ship with an execution engine are built for operators watching a run go green or red. They are not built for the person who needs to see the shape of the flow, follow a decision, and reason about why the agent branched the way it did.
#3 Iteration
Tuning a model choice, a retrieval step, or a single prompt at step ninety-two of a long agent means editing code and shipping a deploy. The loop is slow, and slow loops are where good ideas die.
So the open question that this whole shift leaves on the table is simple.
If durable execution is the reliability infrastructure, what is the authoring infrastructure?
This does not mean every team needs a new workflow UI. It means the category now has two separate questions: how the work runs, and how humans design, inspect, and change it.
Workflow Builder is one answer to the second question.
It is a visual editor and a reference adapter for whatever durable execution you choose, whether that is Temporal, Inngest, Restate, LangGraph, or something you built in house.
It does not replace the engine. It pairs with it.
You keep the execution guarantees you already trust, and you add a visual layer your team can read, edit, and embed in your own product. The reliability lives in the engine. The authoring lives in the editor. Two layers, two jobs, no fight over which one wins.
The licensing needs to be clear too, because teams are right to worry about building critical workflows on top of a locked runtime.
Workflow Builder Community Edition is open source under Apache 2.0. The reference adapter for the engine ships with it, on a public repository, from day one. You are not locked into a runtime, and you are not locked into us.
What it means
- For builders: choose your durable execution engine on its merits, then decide, as a separate question, how the workflow gets authored and seen. Those are two decisions, not one. Teams that collapse them into one end up with a reliable back end and a flow that only the original engineer can read.
- For investors: the reliability layer is funded and forming, with Temporal now valued at $5B. The authoring layer above it is less settled. That is where the next contest sits. Visual canvas patterns are already being absorbed into broader agent and workflow tooling, so the window to define a clear, independent authoring slot looks narrow. Keep the “twelve to eighteen months” line only if the ICP work gives you a source for it.
- For the category: 2024 was the year of the model. 2026 is the year of the system. The teams that internalize that ship agents that survive a bad night in production. The teams that do not keep rebuilding the same plumbing and calling it progress.
If you are building on durable execution and have not solved the authoring layer, that is the next problem worth your time. Try the editor, read the code-first walkthrough, and look at the reference adapter on the public repo.
Keep your engine. Make the workflow visible.
An entrepreneur and tech enthusiast, with over 14 years of experience building innovative diagramming solutions and tools across industries. Our interfaces help technical and non-technical users make informed business decisions.


Go further with Overflow and Workflow Builder
Workflow Builder is powered by Overflow — a library of interaction components made with React Flow that elevates and extends node-based interfaces.

Articles you might be interested in

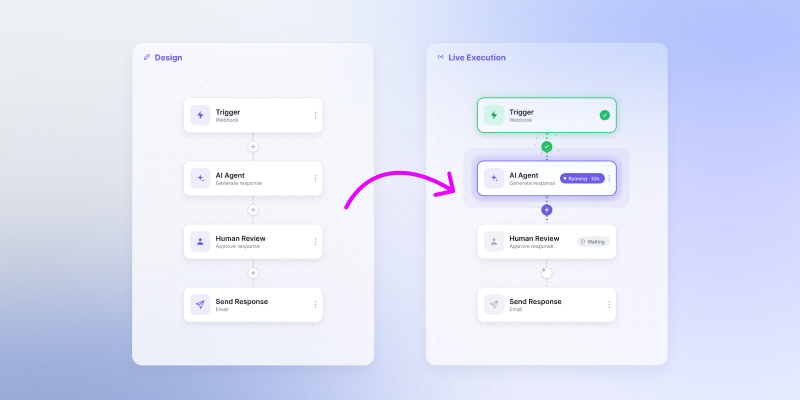
Live workflow execution visualization: why users need to see what is happening
Most workflow products tell users a run “succeeded” or “failed” after the fact. A live, on-canvas execution view shows what is happening in real time, on the same canvas users authored on — and that is where product trust gets built.

{kind=link}